Database는 간단히 데이터들의 모임 이라고 보면 된다.
아래의 속성들을 충족해야 한다.
- 의존성
- 일관성
- 보안성
- 경제성
- 무결성
결론
뜬금없이 두괄식 정리를 해본다.
| Database | 장점 | 단점 |
|---|---|---|
| HDB | 구조가 간단하고 판독이 용이하다. | 데이터 상호 간의 유연성이 부족하다. |
| 구현, 수정, 검색이 용이하다. | 검색 경로가 한정되어 있다. | |
| 데이터 액세스 속도가 빠르다. | 삽입/삭제 연산이 매우 복잡하다. | |
| 데이터의 사용량을 쉽게 예측 가능하다. | 다 대 다 관계를 처리하기 어렵다. | |
| NDB | 상하 종속적인 관계를 쉽게 해결한다. | 구성, 설계가 복잡하다. |
| 데이터의 종속성을 해결하지 못한 시스템이다. | ||
| RDB | 데이터의 일관성을 보증할 수 있음. (Transaction) | 대량 데이터 처리 시 성능 이슈. |
| 정규화를 전제로 하기 때문에 갱신 시의 비용이 적게 든다. | 갱신이 발생한 Table의 인덱스 생성이나 스키마 변경에 대한 처리 이슈. | |
| JOIN 등 복잡한 검색 조건으로 검색이 가능함. | Column을 확실히 정의하기 어려운 경우에 대한 처리 이슈. | |
| 간결하고, 보기 편하다. | 단순히 빨리 결과를 조회하고자 할 때의 성능 이슈. | |
| OODB | ||
| NoSQL | 대량의 Record 처리에 유리하다. | JOIN 연산이 불가능하다. |
Database의 구성요소
- Database
- Schema
- DBMS (Database Management System)
- Database Language
- Database Storage
- User
Database의 종류
- File System - File type
- HDB (Hierachical Database, 계층형 데이터베이스) - Segment type
- NDB (Network Database, 네트워크형 데이터베이스) - Record type
- RDB (Relational Database, 관계형 데이터베이스) - Table type
- OODB (Object-Oriented Database 객체지향형 데이터베이스) - Class type
- NoSQL (Not only SQL)
Database의 종류
File System
말 그대로 파일시스템을 의미한다.
HDB (Hierachical Database)
- 트리구조를 기반으로 하는 계층형 데이터 모델을 사용한다.
- 데이터는 트리 형태로 구성되며 각 데이터 요소(Entity)들은 상하 관계를 나타내는 Link로 구성된다.
- 제품
- Adabas
- GT.M
- IMS
- MUMPS
- Cache
- Metakit
- Multidimensional hierachical toolkit
- Mumps compiler
- DMSII
- FOCUS
NDB (Network Database)
- 그래프 구조를 기반으로 하는 네트워크형 데이터 모델을 사용한다. 이는 Entity와 Entity 간의 Relationship을 그래프로 연결한다.
- HDB와 비슷하지만 부모(상위 Entity)를 여러 개 가질 수 있다.
- 제품
- IDS
- IDMS
- RDM Embedded
- RDM Server
- 터보이미지
- 유니박 DMS-1100
RDB (Relational Database)
- 현재까지 가장 안정적이고 효율적인 Database로 알려져있다.
- Entity를 Table로 사용하고 Entity 간의 공동 Attribute를 이용하여 서로 연결하는 독립된 형태의 데이터 모델이다.
- SQL을 사용한다.
- 제품
- Oracle (Oracle)
- MS-SQL Serve (Microsoft)
- MySQL (Oracle -SunMicroSystems-)
- DB2 (IBM)
- Infomix (IBM)
- Sybase (Sybase)
- Derby (Apache)
- SQLite (Opensource)
OODB (Object-Oriented Database)
- Class, Object, Attribute, Method, Instance, Capsulation, Inheritance 등을 기반으로 데이터를 구조화하는 데이터 모델이다.
- 비지니스형 데이터 타입만 처리되는 RDBMS의 기본적인 제한점을 극복하기 위해 고안되었다.
NoSQL (Not only SQL)
- SQL을 사용하지 않는다는 뜻이다.
- Schema가 없다.
- 대용량 데이터 처리에 유리하고 분산 처리가 가능하여 Cloud computing에 유리하다.
- 종류
- Key/Value type
- Memchached
- Tokyo Tyrant
- Flare
- Roma
- Redis
- Document type: 여러가지 형태의 값들을 모아둔 논리적 구조.
- MongoDB
- CouchDB
- Big Table (Column) type: RDB는 Row 단위로 데이터를 관리하지만 Colume type은 Column 단위로 데이터를 관리한다.
- HBase
- Casandra
- Hypertable
- Key/Value type
Schema (Meta-Data)
Database의 구조 및 제약 조건에 대해 전반적으로 기술한 것을 Schema라고 한다.
Entity(Table), Attribute(Field), Relationship 및 데이터 조작 시 데이터 값들이 갖는 제약 조건 등에 대해 정의한다.
Schema는 Data Dictionary에 저장된다.
쉽게 말해 Data structure가 어떻게 생겼는지 정의하며, RDB에서는 아래 코드처럼 생겼다.
|
|
DBMS
기존 파일 시스템이 갖는 데이터 종속성과 중복성 문제를 해결하기 위해 제안된 시스템으로 모든 Application들이 Database를 공용으로 사용할 수 있도록 관리한다.
DBMS의 궁극적 목표는 데이터의 독립성이다.
논리적 독립성:Application과Database를 독립시켜 Data에 변경이 발생하여도 Application은 변경되지 않는다.물리적 독립성:Application과Storage를 독립시켜 디스크에 변경이 발생하여도 Application은 변경되지 않는다.
DBMS의 필수 기능
정의 (Definition): Type 및 Structure에 대한 정의, 이용 방식, 제약 조건을 정의한다.조작 (Manipulation): 데이터의 검색, 갱신, 삽입, 삭제 등의 처리를 위해 User와 Database 사이의 Interface를 제공하는 것을 의미한다.제어 (Control): 데이터의 정확성, 무결성, 보안 및 권한 검사, 병행수행 제어 등의 기능을 정한다.
Releationship (관계)
- 일 대 일
- 일 대 다
- 다 대 다
Key
조건을 만족하는 Tuple을 찾거나 순서대로 정렬할 때 Tuple들을 구분할 수 있는 기준이 되는 Attribute를 의미한다.
Candidate Key (후보키)
Relation을 구성하는 Attribute들 중에서 Tuple을 식별하기 위해 사용하는 Attribute들의 부분 집합을 의미한다. Primary Key로 사용할 수 있는 Attribute이다.
ex) 주민 Relation에서의 주민등록번호 또는 지문
- 유일성 (Unique): 하나의 Key 값으로 하나의 Tuple만을 식별할 수 있어야 한다.
- 최소성 (Minimality): 모든 Record들을 유일하게 식별하는데 꼭 필요한 Attribute들로만 이루어져야 한다.
Primary Key (기본키)
Candidate Key 중 선택한 Main Key를 의미하며 NULL 이 될 수 없다.
Alternate Key (대체키)
Candidate Key가 두 개 이상일 때 Primary Key를 제외한 나머지 Candidate Key들을 의미하며 보조키라고도 부른다.
Super Key (슈퍼키)
하나의 Table 내에 있는 Attribute들의 집합으로 구성된 Key를 말한다. Table을 구성하는 모든 Tuple 중 Super Key로 구성된 Attribute의 집합과 동일한 값은 나타나지 않는다.
Super Key는 Table을 구성하는 모든 Tuple에 대해 유일성은 만족시키지만 최소성은 만족시키지 못한다.
Foreign Key (외래키)
두 개의 Table이 Relationship을 맺고있을 때 A의 Primary Key와 같은 B의 Attribute 를 Foreign Key 라 부른다.
즉, 아래 그림에서 A가 B를 참조한다고 하면 B의 주민등록번호는 Primary Key가 되고 A의 주민등록번호는 Foreign Key가 된다.
Field가 적어서 예시가 적절하지 않은 것도 같고…
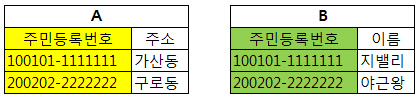 {:class=”img-responsive”}
{:class=”img-responsive”}
Foreign Key를 사용하면 실수로 Data를 삭제하는 것을 막을 수 있다. 다른 Table의 Foreign Key로 참조하고 있는 Row는 Table에서 삭제할 수 없기 때문이다. 이를 참조 무결성(Reference Integrity)이라고 부른다.
Integrity (무결성) 이란 데이터를 보호하고 항상 정상인 상태를 유지하는 것을 말한다.
- 개체 무결성
- Table에서 Primary Key를 구성하는 Attribute는 NULL이나 중복값을 가져서는 안 된다.
- 참조 무결성
- Foreign Key의 값은 NULL이나 참조 Table의 Primary Key값과 동일해야 한다. 즉, Table은 참조할 수 없는 Foreign Key의 값을 가질 수 없다. (실수로 삭제하는 것을 예방할 수 있는 이유이다.)
- Foreign Key와 참조하려는 Table의 Primary Key는 Domain과 Attribute의 개수가 같아야 한다.
Transaction
한 단위를 이루는 일련의 연관된 데이터베이스 조작.
하나의 Transaction에 속하는 작업 중 하나라도 실패하면 Transaction 전체가 실패한 것으로 간주하여 변경한 내용을 모두 원래대로 되돌려 놓는다. 이를 Rollback이라 한다.
모든 작업이 성공적으로 처리되면 모든 변경 내용을 한꺼번에 반영하고 이를 Commit이라 한다.
- Transaction의 특성 (ACID)
- Atomicity (원자성)
- Transaction에 포함된 모든 작업이 성공적으로 처리되지 않으면 어떠한 작업도 처리되지 않아야 한다.
- Consistency (일관성)
- Transaction의 시작 전과 종료 후의 Database가 일관된 상태를 유지해야 한다. 참조 무결성이 깨져서는 안된다.
- Isolation (고립성)
- 하나의 Transaction에서 Database를 변경한 내용은 Transaction이 Commit될 때까지 다른 어떤 Query나 Transaction과도 고립되어야 한다.
- Durability (영속성)
- Commit이 이루어지면 Transaction에 의해 변경된 내용은 영구적으로 유지되어야 한다. DBMS는 Database의 현재 상태가 유실되지 않도록 시스템 충돌 등의 문제로부터 복구할 수 있는 방안을 갖춰야 한다.
- Atomicity (원자성)
용어
TableRelation(관계)또는Entity(개체)라 부른다.Column(열, ↕) 과Row(행, ↔) 으로 구성된다.
FieldAttribute(속성)이라고도 한다.Table의Column을 의미한다.
Degree(차수)Attribute의 수를 뜻한다.
RecordTuple이라고도 하며Table의Row를 의미한다.
Cardinality- 하나의
Relation을 구성하는Tuple(Record)의 수를 의미한다.
- 하나의
Domain- 하나의
Attribute가 가질 수 있는같은 type의 Atomic(원자) 집합을 의미한다.- 예)
학생relation에서학년의domain은1 ~ 6이다.
- 예)
- 하나의
DBMS (Database Management System)DDL (Data Definition Language)- 테이블을 생성하고 삭제하는 언어를 뜻한다.
- CREATE, ALTER, DROP
DML (Data Manipulation Language) = 서브 언어- User가 데이터를 처리할 수 있게 도와주는 도구.
- SELECT, INSERT, UPDATE, DELETE
DCL (Data Control Language)- 데이터의 보호, 관리를 위해 사용된다.
- COMMIT, ROLLBACK, GRANT, REVOKE
Scale up- 사용 중인 서버를 고성능으로 바꿔 처리 능력을 향상시키는 방법으로 비용이 발생하지만 소스에 대한 변경이 없다.
Scale down- 저가의 여러 장비를 사용하여 능력을 향상시키는 방법으로 소스에 대한 수정이 필요하다. 주로 NoSQL에서 제공하는 방식이다.
출처
아래의 글들을 교재삼아 작성하였습니다.